3 Examples to Write Multiple Data Frames in Excel by Pandas/Python
In Pandas Data Frame to Excel tutorial, we learned how to write one data frame into Excel sheet. In this tutorial, we are going to show you how to write multiple data frames by executing a Python program once only.
Writing multiple data frames in Excel
In Pandas Data Frame to Excel tutorial, we learned how to write one data frame into an Excel sheet.
In this tutorial, we are going to show you how to write multiple data frames by executing a Python program once only.
For that, we will use Pandas ExcelWriter and data frame’s to_excel method.
Program for storing two data frames into an Excel file
For two data frames, we have two lists in the program below.
Both lists contain employee information for the demo only. In real situations, data can be of different types to be stored in Excel sheets by multiple data frames.
The code:
import pandas as pd
#First Data Frame's data
employee_list = [ [1, "Mike", 5000],
[2, "Michelle", 4500],
[3, "Mina", 3000]
]
#Second Data Frame's data
employee_list2 = [ [7, "Lerry", 5000],
[8, "Shiza", 4500],
[9, "Mr X", 3000]
]
df_1 = pd.DataFrame (employee_list, columns = ['Employee ID', 'Employee Name', 'Salary'])
df_2 = pd.DataFrame (employee_list2, columns = ['Employee ID', 'Employee Name', 'Salary'])
with pd.ExcelWriter('test_multiple.xlsx', engine='xlsxwriter') as writer:
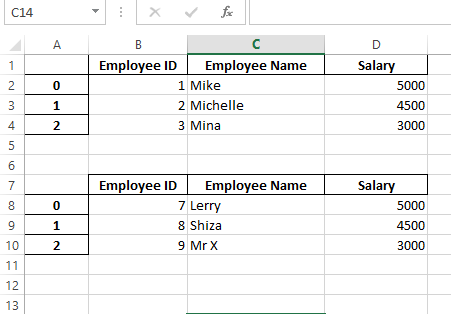
df_1.to_excel(writer, sheet_name='Employees', startrow=0, startcol=0)
df_2.to_excel(writer, sheet_name='Employees', startrow=1+len(df_1)+2, startcol=0)
Output:
How did it work?
- Imported the Pandas library
- Created two lists for Pandas data frames
- In each data frame, column names are given along with the list. So, you may use columns for each DF separately.
- Pandas ExcelWriter object is used where we specified the Excel file name.
- In Data Frame’s to_excel method, we specified sheet names for each DF.
- In to_excel, you may specify what should first row and column.
- For the second DF, we specified start row below two rows to the first DF. You should change it as per need.
Do not include column names for the second data frame
Well, if you have a similar type of data then you may not want to display the column headers for the second data frame.
However, if we just omit this in the above code, i.e.:
import pandas as pd
#First Data Frame's data
employee_list = [ [1, "Mike", 5000],
[2, "Michelle", 4500],
[3, "Mina", 3000]
]
#Second Data Frame's data
employee_list2 = [ [7, "Lerry", 5000],
[8, "Shiza", 4500],
[9, "Mr X", 3000]
]
df_1 = pd.DataFrame (employee_list, columns = ['Employee ID', 'Employee Name', 'Salary'])
#DF 2 without column headers
df_2 = pd.DataFrame (employee_list2)
with pd.ExcelWriter('test_multiple.xlsx', engine='xlsxwriter') as writer:
df_1.to_excel(writer, sheet_name='Employees', startrow=0, startcol=0)
df_2.to_excel(writer, sheet_name='Employees', startrow=1+len(df_1)+2, startcol=0)
Result:
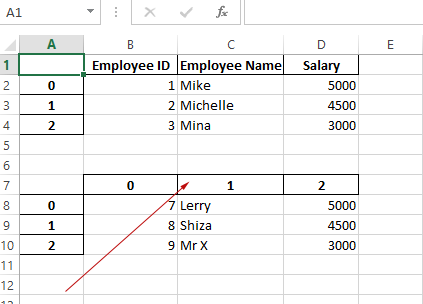
You can see, it displays a column index starting at 0.
In order to avoid this entirely, simply add the following in the df_2 data frame: header=False.
This is added when you write to the Excel file as given below.
Code:
import pandas as pd
#First Data Frame's data
employee_list = [ [1, "Mike", 5000],
[2, "Michelle", 4500],
[3, "Mina", 3000]
]
#Second Data Frame's data
employee_list2 = [ [7, "Lerry", 5000],
[8, "Shiza", 4500],
[9, "Mr X", 3000]
]
df_1 = pd.DataFrame (employee_list, columns = ['Employee ID', 'Employee Name', 'Salary'])
df_2 = pd.DataFrame (employee_list2, columns = ['Employee ID', 'Employee Name', 'Salary'])
with pd.ExcelWriter('test_multiple.xlsx', engine='xlsxwriter') as writer:
df_1.to_excel(writer, sheet_name='Employees', startrow=0, startcol=0)
df_2.to_excel(writer, sheet_name='Employees', startrow=1+len(df_1)+2, startcol=0, header=False)
Output:
Avoiding Index column example
You may also notice the index column displaying 0, 1, 2 in the “A” column for each data frame. This is because of the index attribute of the data frame whose default value is:
index=True
As we have not given it in any data frame, so Pandas used it and we have A index column.
The following program removed the index column from both data frames:
import pandas as pd
#First Data Frame's data
employee_list = [ [1, "Mike", 5000],
[2, "Michelle", 4500],
[3, "Mina", 3000]
]
#Second Data Frame's data
employee_list2 = [ [7, "Lerry", 5000],
[8, "Shiza", 4500],
[9, "Mr X", 3000]
]
df_1 = pd.DataFrame (employee_list, columns = ['Employee ID', 'Employee Name', 'Salary'])
df_2 = pd.DataFrame (employee_list2, columns = ['Employee ID', 'Employee Name', 'Salary'])
#Making index= False for both data frames. header=False for second DF only
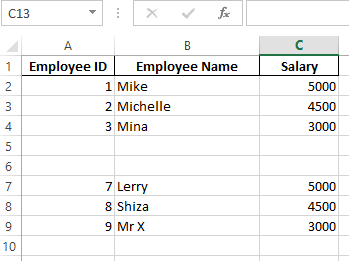
with pd.ExcelWriter('test_multiple.xlsx', engine='xlsxwriter') as writer:
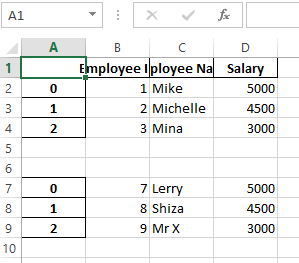
df_1.to_excel(writer, sheet_name='Employees', startrow=0, startcol=0, index=False)
df_2.to_excel(writer, sheet_name='Employees', startrow=1+len(df_1)+2, startcol=0, header=False, index=False)
Output:
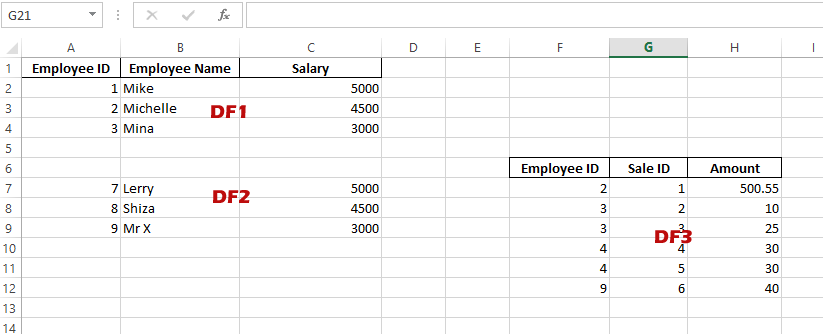
Using three Data frames example
We added another data frame to the above example with its own column names and other attributes. See the code and output:
import pandas as pd
#First Data Frame's data
employee_list = [ [1, "Mike", 5000],
[2, "Michelle", 4500],
[3, "Mina", 3000]
]
#Second Data Frame's data
employee_list2 = [ [7, "Lerry", 5000],
[8, "Shiza", 4500],
[9, "Mr X", 3000]
]
#Third Data Frame's data
Sales_list = [ [2, 1, 500.55],
[3, 2, 10],
[3, 3, 25],
[4, 4, 30],
[4, 5, 30],
[9, 6, 40]
]
df_1 = pd.DataFrame (employee_list, columns = ['Employee ID', 'Employee Name', 'Salary'])
df_2 = pd.DataFrame (employee_list2)
df_3 = pd.DataFrame (Sales_list, columns = ['Employee ID', 'Sale ID', 'Amount'])
with pd.ExcelWriter('test_multiple.xlsx', engine='xlsxwriter') as writer:
df_1.to_excel(writer, sheet_name='Employees', startrow=0, startcol=0, index=False)
df_2.to_excel(writer, sheet_name='Employees', startrow=1+len(df_1)+2, startcol=0, header=False, index=False)
df_3.to_excel(writer, sheet_name='Employees', startrow=1+len(df_1)+1, startcol=5, index=False)
Output: