How to Read Excel Files by Pandas read_excel
Reading Excel files in Pandas – A Python library
Pandas is a Python library that is used:
- For data science
- Data analysis
- Analyzing data
- Cleaning data
- Exploring and manipulating data
If we are talking about data, how come Excel is not covered?
Pandas has a method read_excel() that enables us to read the Excel files (xls, xlsx, xlsm, xlsb, odf, ods and odt file extensions).
The Pandas read_excel() has plenty of parameters that you may pass to fetch the data as per need.
You may load:
- Whole sheet data
- Multiple sheets data
- Merge data
- Exclude a certain number of rows from the sheet(s)
- Fetch only specific top rows
- Return only a few bottom row
- And many more
In this tutorial, we will show you examples of loading and reading Excel files with a few options (one by one), so keep reading.
An example of loading and displaying Excel sheet
For our examples, we will use the following Excel sheet with the .xlsx extension.
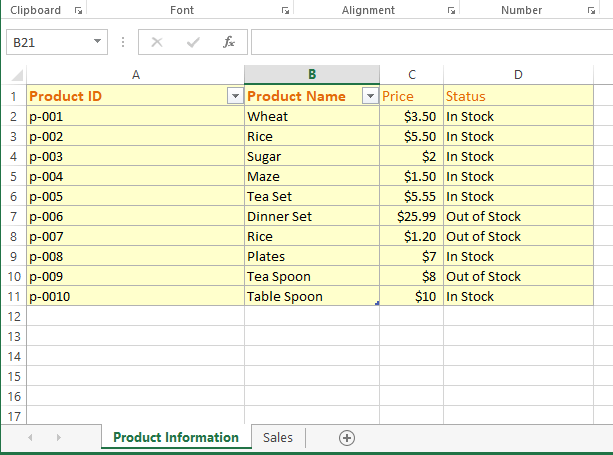
It has two sheets namely:
- Product Information
- Sales
The first example reads data from the “Product Information” sheet:
Note: If you have not installed the pandas package yet, just write this line in the CMD (or command line)
$ pip install pandas
Python code to read Excel file:
import pandas as pd
#loading excel file by read_excel method
dt_frame = pd.read_excel('test_Excel.xlsx')
#Display first sheet
print(dt_frame)
Output:
Product ID Product Name Price Status 0 p-001 Wheat 3.50 In Stock 1 p-002 Rice 5.50 In Stock 2 p-003 Sugar 2.00 In Stock 3 p-004 Maze 1.50 In Stock 4 p-005 Tea Set 5.55 In Stock 5 p-006 Dinner Set 25.99 Out of Stock 6 p-007 Rice 1.20 Out of Stock 7 p-008 Plates 7.00 In Stock 8 p-009 Tea Spoon 8.00 Out of Stock 9 p-0010 Table Spoon 10.00 In Stock
Two things to notice in the above output:
- By default, read_excel only loaded the first sheet's data.
- It also added row numbers (0,1,2…) which is index column
So, we will address both in the examples below.
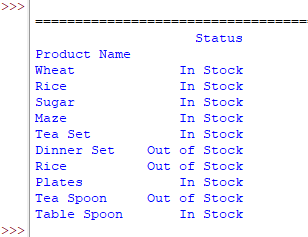
How to omit index column from the data frame
The read_excel has a parameter index_col that you may use to omit the first column that contains the row number.
Its default value is None i.e. index_col=None
By using index_col=0 we get the output as follows:
Code:
import pandas as pd
#Loading excel file without index column
dt_frame = pd.read_excel('test_Excel.xlsx',index_col=0)
#Display first sheet
print(dt_frame)
Output:
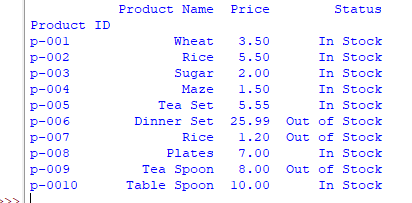
Using the values example
Alternatively, you may get the Sheet rows without index columns as follows:
Code:
import pandas as pd
#Loading excel file without index column
dt_frame = pd.read_excel('test_Excel.xlsx')
#Display first sheet with values
print(dt_frame.values)
Output:
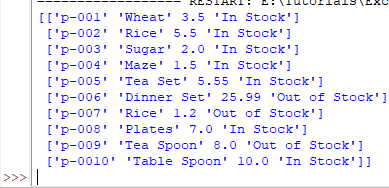
Reading Excel file by sheet names - sheet_name parameter
The following example specifies the sheet in our Excel Workbook. We will fetch records of the “Sales” sheet by number.
For that, sheet_name parameter is used where you may specify the sheet number from 0. In our case,
- 0 = Product Information
- 1 = Sales
The program below loads data from Sheet 1 i.e. Sales.
Python code:
import pandas as pd
#Loading excel file by sheet number
dt_frame = pd.read_excel('test_Excel.xlsx', sheet_name=1)
#Display sheet numebr 1(Sales) data
print(dt_frame)
Output:
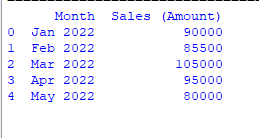
Loading data by sheet name rather than number
Similarly, you may specify the sheet name rather number of sheet in the Workbook.
The example below loads data of “Product Information” by using sheet_name and omitting the index column:
import pandas as pd
#Loading excel file by sheet name
dt_frame = pd.read_excel('test_Excel.xlsx', sheet_name='Product Information',index_col=0)
#Display sheet name = Product Information data
print(dt_frame)
Result:
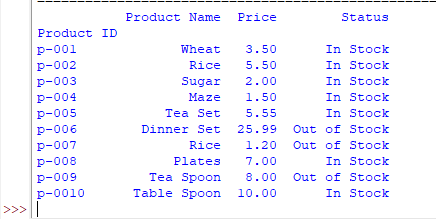
Loading two (multiple) sheets example
import pandas as pd
#Loading multiple sheets without index column
dt_frame = pd.read_excel('test_Excel.xlsx', sheet_name=['Sales','Product Information'],index_col=0)
#Display sheet name = Product Information and Sales data
print(dt_frame)
Result:
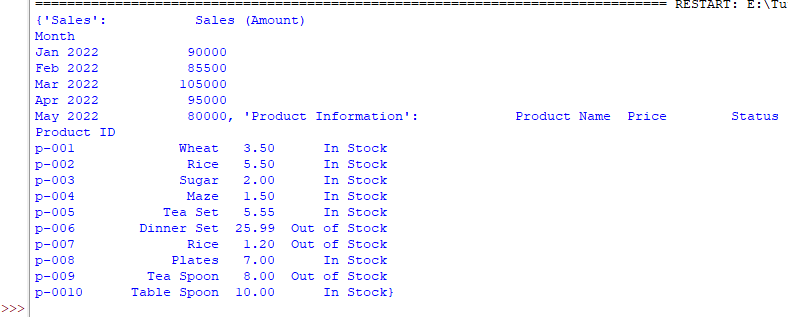
Display only column headers
Though this will be deprecated in the next version, let us show you how to get headers only from the sheet:
import pandas as pd
#loading excel file by read_excel method
dt_frame = pd.read_excel('test_Excel.xlsx')
#Display only headers
print(dt_frame.columns.ravel())
Output:
['Product ID' 'Product Name' 'Price' 'Status']
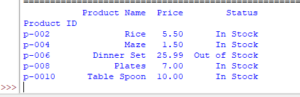
Get only specific columns example
import pandas as pd
# Return only specific columns
dt_frame = pd.read_excel('test_Excel.xlsx', index_col=0, usecols=['Product Name', 'Status'])
#Display columns data
print(dt_frame)
Output: