Add/Remove Index Column by Pandas read_excel index_col parameter
The read_excel method has a parameter index_col which default value is: index_col=None
Other values supported are int, list of int.
What is Index Column as using Pandas to Read Excel Files
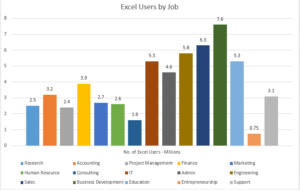
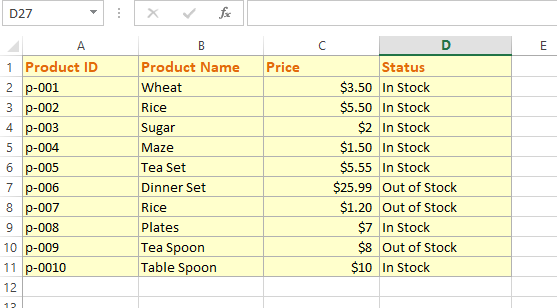
First, let us show you our sample Excel file (Workbook) loaded in Python by Pandas read_excel method.
Code
import pandas as pd
#Loading excel file without index column
dt_frame = pd.read_excel('test_Excel.xlsx',index_col=None)
#Display first sheet
print(dt_frame)
Output:
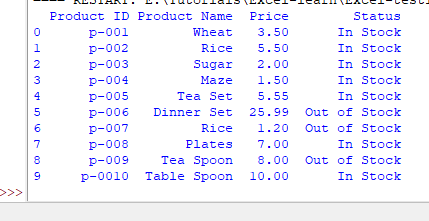
In the above output, you can see a column is added by Pandas as we are reading a Workbook sheet.
This column containing row numbers is called index column.
In certain scenarios, it may be unnecessary to have this column in our output.
So how to hide/remove this from the returned results?
Excluding default Index column example
The read_excel method has a parameter index_col whose default value is:
- index_col=None
- Other values supported are int, list of int.
- It is used as the row- label of the Data Frames.
- Its index starts at 0
As using None (default), it returns the rows as shown in the above graphic – with an index column.
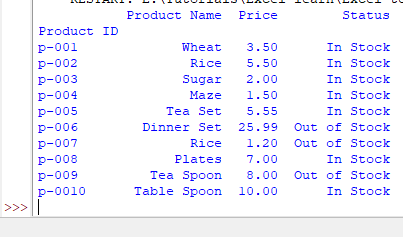
By using index_col = 0, the first column from the Excel sheet is taken as the index column.
See an example below where we used it:
import pandas as pd
#Loading excel file without index column = 0
df_prods = pd.read_excel('test_Excel.xlsx',index_col=0)
#Display first sheet
print(df_prods)
Output:
What if we use 1 or another value
See the example below where we assigned index_col=1:
import pandas as pd
#Using index_col = 1
df_prods = pd.read_excel('test_Excel.xlsx',index_col=1)
#Display first sheet
print(df_prods)
Result:
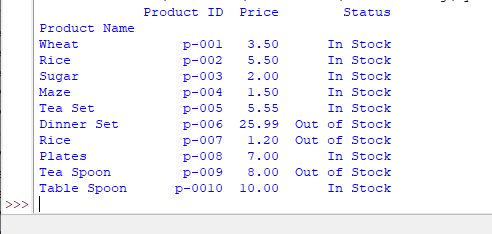
As index_col is 0-based index, so 1 means the second column from our Excel sheet - is taken as the Index column.